Power BI – Fuzzy Match Similarity Threshold
By: David Rohlfs
Introduction
When you are working in Power Query, there are a lot of times where you need to merge queries together and the data might not have perfectly matching key columns. When this happens you probably turn to fuzzy matching. But when the fuzzy match does not work correctly the first time, you start experimenting with the similarity threshold.
This blog will not be going over the basics of a merge or a fuzzy match. If you want to learn more about these topics, there will be helpful links to similar blogs below.
In this blog we will go over what the similarity threshold is and how it affects a fuzzy match merge. We will not be doing a walkthrough of this concept. For instructions on doing a Fuzzy Match, see related blogs below.
When to use it
To understand how the similarity threshold works, it is important to understand what the fuzzy logic algorithm is doing to create the merge. What a fuzzy match/fuzzy logic is doing is finding the percentage of similarity between each of the options from table 1 to table 2. In the example, we are using a similarity threshold of 0.1. So, “Chicken Tikka Masla” is matching with “Tikka Masala” and with “Chicken Caesar Salad”. If we raise the similarity threshold to a value that is greater than the percentage similar between “Chicken Tikka Masala” and “Chicken Caesar Salads” but less than the percentage similar between “Chicken Tikka Masala” and “Tikka Masala” we can exclude the value “Chicken Caesar Salads” from the table altogether.
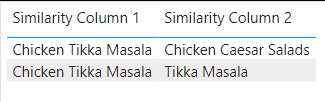
Now that we have built the understanding of where we get the similarity percentages from, we can dive into what the similarity threshold option is and how it works. The similarity threshold is used as the minimum percentage of likeness between values in key columns when doing a fuzzy match merge. The default similarity threshold value is 0.80. You can change this value by entering a number between 0 and 1 in the similarity threshold box while in the merge pop out.

When you have a lower similarity threshold, you will get more matches per value from Table A to Table bB. So, having a lower similarity threshold increases your chances of getting a match.
If you enter a value of 1 into the similarity threshold this will create what is called an exact match. Meaning that a value from Table A must exactly match a value from Table B to match for the merge. So, having an exact match essentially creates a situation where you are using a fuzzy match, but the merge acts as a normal merge. This is a good method to utilize some of the other fuzzy match options like case sensitivity and maximum number of matches without having unwanted matches.
Having a value of 0 as the similarity threshold does not mean that all values from Table A will be matched with Table B. Understanding why this works goes back to the use of the fuzzy logic algorithm being used inside of power query. A value from Table A does not necessarily have any correlation to a value from Table B, so it will not go through the fuzzy logic algorithm. I am not sure why this is the case, but it just is. Regardless of this, it is extremely unlikely that you will ever use a similarity threshold of 0 because it creates many undesirable matches among your data.
Now that we understand a lot about the similarity threshold’s importance to a fuzzy match, let’s get into an example showing why you should play with your similarity threshold. In this example we have a key column from Table 1 and from Table 2 that we are using a fuzzy match to merge together. Notice that none of the values are alike so I did not do a merge with an exact match (1.0 Similarity Threshold).

Merged Table 1 has a similarity threshold of 0.8, which is the default value, and has 5 of 10 possible matches. If we decrease the similarity threshold to 0.5, we get Merged Table 2. And with a similarity threshold of 0.1 we get Merged Table 3. Notice that Merged Tables 1 & 2 both have a significant percentage of rows that don’t have a match. But Merged Table 3 has a match “Similarity Column 1 ‘Chicken Tikka Masala’” that has been duplicated because it has a similarity greater than 0.1 for two different values.
Understanding that you may have duplicated values if you have a similarity threshold that is too small is very important. You can mitigate this risk by using the Maximum Number of Matches feature, but this doesn’t always work for every situation (see blog below). Finding what similarity threshold works for your situation is important because you may not have the luxury of just being able to do a match with the default similarity threshold value.
Conclusion
We covered a very complex topic in this blog that can be hard to fully understand. If you want to see other examples of how the similarity threshold affects your merging, I suggest reading through some of the other blogs linked below. Finding the perfect similarity threshold can be a lengthy process, but thankfully many situations don’t require the use of a fuzzy match.
Links to Contain:
Fuzzy Mach Maximum Number of Matches
Comments
2 Responses to “ Power BI – Fuzzy Match Similarity Threshold ”
[…] Fuzzy Match Similarity Threshold […]
[…] Fuzzy Match Similarity Threshold […]
Leave a Reply
You must be logged in to post a comment.